

Five qualities of A.I. apps
PLUS: Make a podcast about your groupchat!

Greetings from Read Max HQ! I was on NPR last week discussing Zyn. And if you haven’t read it yet, let me re-plug my New York magazine feature on A.I. slop.
In today’s newsletter:
Assessing Google’s cool new A.I. product NotebookLM;
creating A.I.-generated podcasts out of your group chats;
the problem with A.I.-generated summaries;
and more!
A reminder: Read Max is 99.5 percent funded by the generosity of paying readers. I treat this newsletter as my full-time job, and spend dozens of hours every week researching, reading, reporting, thinking, procrastinating, and writing, in the hopes of creating something that helps people understand the world, or at least helps them kill 10-15 minutes entertainingly. If you gain something from this newsletter, and if you want to support its weekly public availability, please consider upgrading your subscription for the price of about one-third a fancy cocktail ($5) a month, or three or four fancy cocktails ($50) a year.

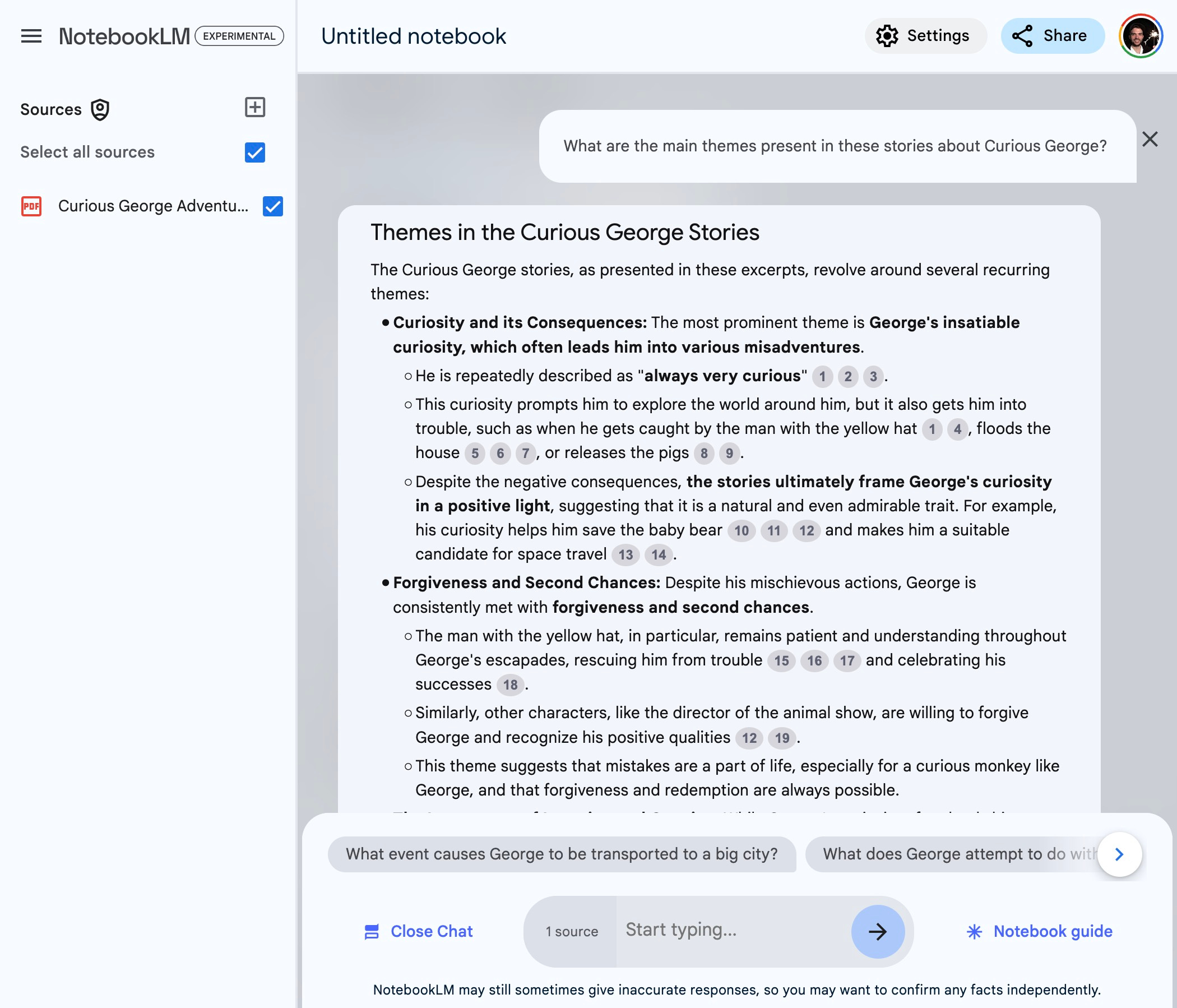
This week’s hot A.I. app--among both the kinds of people who have “hot A.I. apps,” and among college kids on TikTok--is NotebookLM, a Google Labs product to which you can upload “sources”--links, PDFs, MP3s, videos--that then form the basis of a narrowly specific LLM chatbot. For example, if I upload the complete works of a great author of fiction, I can ask questions about characters and themes that span the entire oeuvre, and its answer will come with clear citations:
I can also use it to generate a graduate-level study guide, FAQs, a “briefing,” etc.:

And so on.
NotebookLM has been available for a year or so now, but what’s made it suddenly popular over the last week or so is the discovery of its “audio overview” feature, which creates a short, fully A.I.-generated podcast, in which two realistic A.I.-generated “hosts,” speaking in the chipper and casual tones we associate with professional podcasters, cover whatever’s in your notebook. Here, e.g., is the audio overview for my Curious George notebook:
I like NotebookLM, or, at least, I don’t hate it, which is more than I can say for a lot of A.I. apps. It has a fairly clear purpose and relatively limited scope; its interface is straightforward, with a limited emphasis on finicky “prompting,” and you can imagine (if maybe not put into practice) a variety of productive uses for it. But even if it’s a modest and uncomplicated LLM-based app, it’s still an LLM-based app, which means its basic contours, for better and for worse, are familiar.
The five common qualities of generative-A.I. apps
By this I mean that NotebookLM shares what I think of as the five qualities visible in all the generative-A.I. apps of the post-Midjourney era. NotebookLM, for all that it represents a more practical and bounded LLM experience than ChatGPT or Claude, is in a broad sense not particularly different:
Its popular success is as much (and often more) about novelty and entertainment value than actual utility.
It’s really fun to use and play around with.
Its product is compellingly adequate but noticeably shallow.
It gets a lot of stuff wrong.
It’s almost immediately being used to create slop.
Let me try to explain what I mean, one at a time.
Its popular success is as much (and often more) about novelty and entertainment value than actual utility.
Generative-A.I. apps are almost always promoted as productivity tools, but they tend to go viral (and gain attention and adopters) thanks to entertaining examples of their products. This is not to say that NotebookLM is useless, but I think it’s telling that the most viral and attention-grabbing example of its use so far was the Redditor who got the “podcast hosts” to “realize” that they’re “A.I.,” especially once it was shared on Twitter by Andreessen Horowitz V.C. Olivia Moore.
My hunch in general is that the entertainment value of generative A.I.--by which I just mean the simple pleasure of using and talking to a computer that can reproduce human-like language--is as underrated as the productivity gains it offers are overrated, and that often uses that are presented as “productive” are not actually more efficient, just more fun:
it seems pretty clear to me that these apps, in their current instantiation, are best thought of, like magic tricks, as a form of entertainment. They produce entertainments, yes--images, audio, video, text, shitposts--but they also are entertainments themselves. Interactions with chatbots like GPT-4o may be incidentally informative or productive, but they are chiefly meant to be entertaining, hence the focus on spookily impressive but useless frippery like emotional affect. OpenAI’s insistence on pursuing A.I. that is, in Altman’s words, “like in the movies” is a smart marketing tactic, but it’s also the company meeting consumer demand. I know early adopters swear by the tinker-y little uses dutifully documented every week by Ethan Mollick and other A.I. influencers, but it seems to me that for OpenAI these are something like legitimizing or world-building supplements to the core product, which is the experience of talking with a computer.
Is “generating and listening to a ten-minute podcast about an academic paper” a more efficient way to learn the material in that paper? I would guess “no,” especially given the limitations of the tech discussed below. But is it more entertaining than actually reading the paper? Absolutely, yes.
It’s really fun to use and play around with.
The first thing I did with NotebookLM was, obviously, upload the text of the group chat for my fantasy football league, in order to synthesize the data and use the power of neural networks understand how bad my friend Tommy’s team is this year:

I can’t say the podcast hosts fully understood every dynamic, but they were very clear that Tommy’s team is bad:
Fantasy sports are obviously fertile territory for NotebookLM, but you want to really fuck up some friendships, I highly recommend uploading as much text as possible from a close-friends group chat and unleashing the power of large language models to analyze the relationships, settle disputes, and just generally wreak havoc on the delicate dynamics of a long-term friend group:
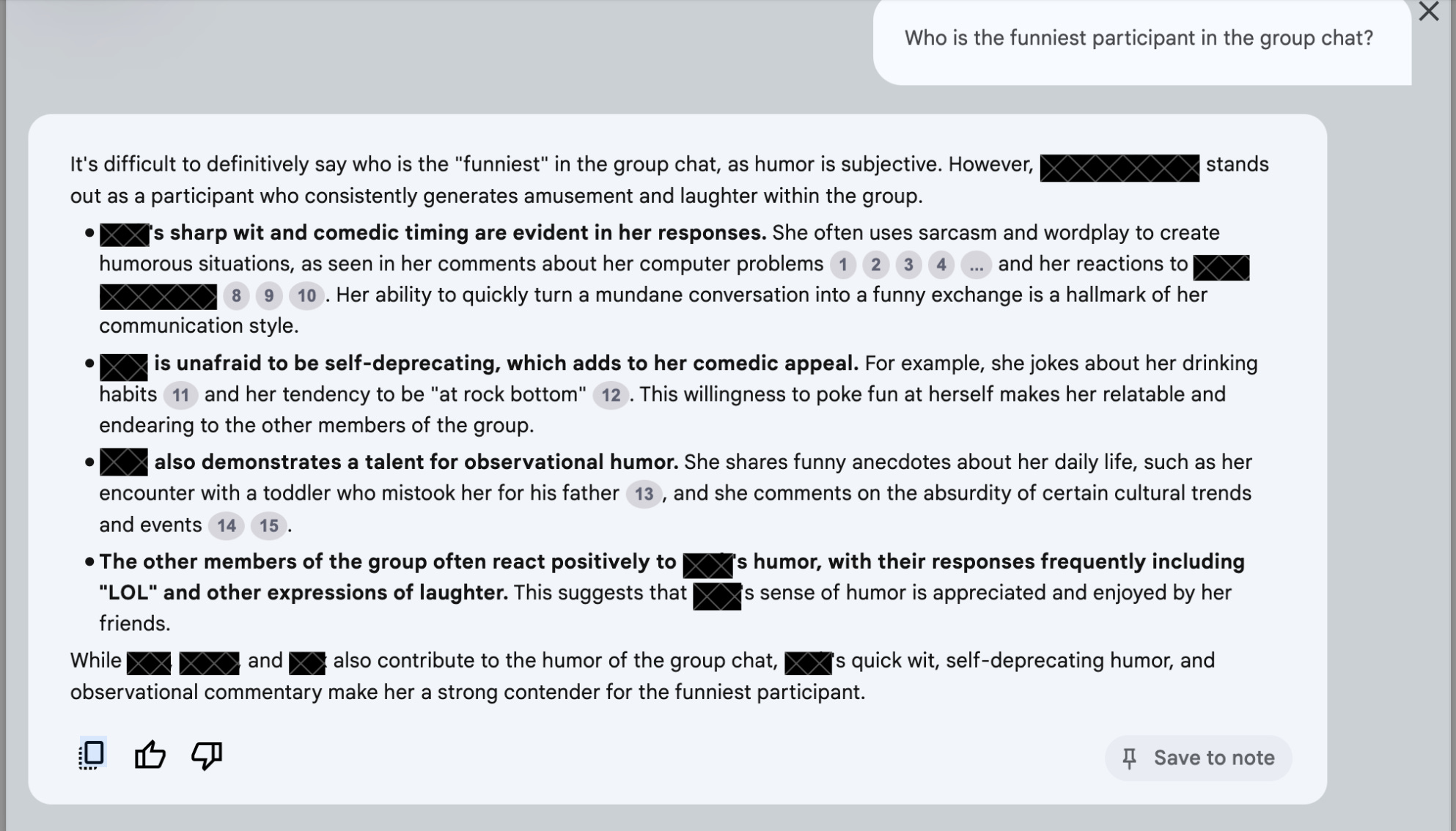
Its product is compellingly adequate, but it’s shallow and gets a lot of stuff wrong.
The answers and syntheses that NotebookLM creates are legible and rarely obviously wrong, and the verisimilitude of the podcast is wild, even if you can hear small glitches here and there.
But the actual quality of NotebookLM’s summaries (both audio and text) is--unsurprisingly if you’ve used any other LLM-based app--inconsistent. Shriram Krishnamurthi asked co-authors to grade its summaries of papers they’d written together; the “podcasters” mostly received Cs. “It is just like a novice researcher: it gets a general sense of what's going on, doesn't always know what to focus on, sometimes does a fairly good idea of the gist (especially for ‘shallower’ papers), but routinely misses some or ALL of what makes THIS paper valuable,” he concludes.
Henry Farrell, who was also unimpressed by the content of the “podcasts,” has a theory about where they go wrong:
It was remarkable to see how many errors could be stuffed into 5 minutes of vacuous conversation. What was even more striking was that the errors systematically pointed in a particular direction. In every instance, the model took an argument that was at least notionally surprising, and yanked it hard in the direction of banality. A moderately unusual argument about tariffs and sanctions (it got into the FT after all) was replaced by the generic criticism of sanctions that everyone makes. And so on for everything else. The large model had a lot of gaps to fill, and it filled those gaps with maximally unsurprising content.
This reflects a general problem with large models. They are much better at representing patterns that are common than patterns that are rare.
This seems intuitively right to me, and it’s reflected in the podcasts, which not only summarize shallowly, often to the point of inaccuracy, but draw only the most banal conclusions from the sources they’re synthesizing. For me, personally, the possibility that I’m consuming either a shallow or, worse, completely incorrect summary of whatever it is I’ve asked the A.I. to summarize all but cancels out the purported productivity gains.
And yet, for a while now it’s seemed like “automatically generated summaries” will be the first widespread consumer implementation of generative A.I. by established tech companies. The browser I use, Arc, has a feature that offers a short summary of a link when you hover and press the shift key, e.g.:
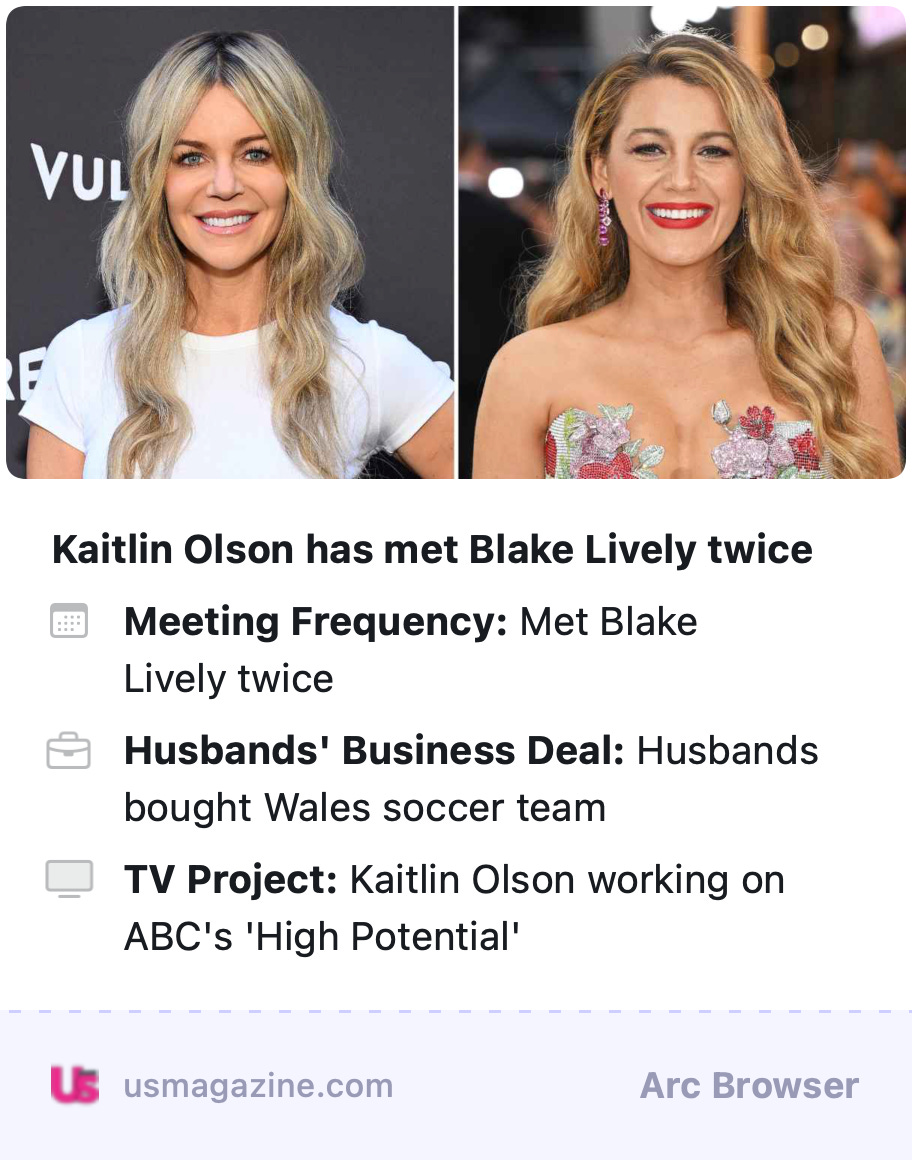
Gmail, of course, is constantly asking me if I want to “summarize” emails I receive, no matter how long; Apple’s new “Apple Intelligence” is touting a feature through which it “summarizes” your alerts and messages, though screenshots I’ve seen make it seem of … dubious worth, at best:

Setting aside the likelihood that the A.I. is getting these summaries wrong (which it almost always will with the kinds of socially complex messages you get from friends), is reading an email or a text or even a whole article really that much of a burden? Is replacing human-generated text with a slightly smaller amount of machine-generated text actually any kind of timesaver? Seeing all these unnecessary machine summaries of communications already smoothed into near-perfect efficiency, it’s hard to not to think about this week’s Atlantic article about college kids who have apparently never read an entire book, which suggests we’re mostly training kids to be human versions of LLMs, passable but limited synthesists, unable to handle depth, length, or complexity:
But middle- and high-school kids appear to be encountering fewer and fewer books in the classroom as well. For more than two decades, new educational initiatives such as No Child Left Behind and Common Core emphasized informational texts and standardized tests. Teachers at many schools shifted from books to short informational passages, followed by questions about the author’s main idea—mimicking the format of standardized reading-comprehension tests. Antero Garcia, a Stanford education professor, is completing his term as vice president of the National Council of Teachers of English and previously taught at a public school in Los Angeles. He told me that the new guidelines were intended to help students make clear arguments and synthesize texts. But “in doing so, we’ve sacrificed young people’s ability to grapple with long-form texts in general.”
Mike Szkolka, a teacher and an administrator who has spent almost two decades in Boston and New York schools, told me that excerpts have replaced books across grade levels. “There’s no testing skill that can be related to … Can you sit down and read Tolstoy? ” he said. And if a skill is not easily measured, instructors and district leaders have little incentive to teach it. Carol Jago, a literacy expert who crisscrosses the country helping teachers design curricula, says that educators tell her they’ve stopped teaching the novels they’ve long revered, such as My Ántonia and Great Expectations. The pandemic, which scrambled syllabi and moved coursework online, accelerated the shift away from teaching complete works.
A Krishnamurthi puts it: “I regret to say that for now, you're going to have to actually read papers.”
It’s almost immediately being used to create slop.
Yes, there are fantasies of productivity, and experiments in shitposting. But all LLM apps trend very quickly toward the production of slop. This week, using NotebookLM, OpenAI founder Andrej Karpathy “curated a new Podcast of 10 episodes called ‘Histories of Mysteries,’” which he generated out of Wikipedia articles about historical mysteries, and uploaded it to Spotify. Moore, the a16z partner, “uploaded 200 pages of raw court documents to NotebookLM [and] created a true crime podcast that is better than 90% of what's out there now...” Enjoy discovering new podcasts? Not for long!
As someone who has been participating in a 2 year long review Gen AI software to use in a corporate legal setting, I have been astounded at the many things these softwares can do that have absolutely little or no value added. "Wow, it can do that?" followed by "and that's a good thing why?".
Usually the why is underwhelming.
I have many extremely real concerns about literacy (I do a lot of test prep tutoring and the challenges I’ve seen in college-bound kids with good grades and affluent patents are pretty alarming), but I found the Atlantic article pretty unconvincing for a number of reasons, chief among them that its evidence that that American schools as a whole have significantly moved away from assigning whole books is pretty thin - I think this tends to be surprising to people who went to schools that did focus on books, but teaching with basal readers has been pretty common in US schools since the 1860s, to the extent that “teach whole books” was a radical progressive idea in the mid-twentieth century, and my understanding is that at any given moment in the past several decades you could find plenty of teachers still doing it. The author characterizes an EdWeek survey as saying “nearly a quarter of respondents said that books are no longer the center of their curricula,” but as far as I can tell from the article linked, the survey says no such thing - it asks about current practices but didn’t ask respondents about whether their practices have changed, so it’s possible that all along a quarter of teachers have mostly been using basals. (This is, to be frank, the exact kind of interpretive error I have to coach eighteen-year-olds out of making on evidence questions.)
It’s honestly wild to me how sloppy the Atlantic is with links… in addition to the survey misinterpretation issue, the author says whole books are disappearing from middle- and high- school programs and links to an article about the implementation in some NYC districts of a a program that is k-6 only, and its link for a phrase about NCLB & Common Core emphasizing informational text links to an NYT piece explicitly about teachers finding ways to integrate & balance informational text with literature (which strikes me as perfectly reasonable). This is pretty standard for the times I’ve tried to fact check major publications (shout out to the Slate advice columnist who dropped a link to a paper about eating disorders that said literally the exact opposite of what she was claiming). It feels a little too mean to say “it’s almost like the writers and editors at certain national publications are already passable but limited synthesists,” but, well…
To speak anecdotally for a minute, I also found the Atlantic article frustrating because it seems to imply the only challenge students are having with complex texts in college is their length… but I regularly meet students who struggle to understand 500 words of a nonfiction passage written for educated laypeople and/or absolutely cannot comprehend even one paragraph of any text more than a hundred years old. Like, the kids in NYC private schools are out there struggling through three sentences from a Lincoln speech. They’re taking ten minutes to slowly, with help, make it through the first two paragraphs of an article such as one might find in Scientific American. The author claims that students at Columbia can decode words and sentences, but I’ve definitely met kids who while not necessarily bound for Columbia are on track for selective private colleges who struggle to figure out unfamiliar words (recent example: “uninhibitedly”) and can’t make it unsupported through a sentence of Austen or the Federalist papers. (I often ask them to identity what a given pronoun refers to, and it’s amazing how hard this is for some of them! They have made it almost to college without having internalized that if you read a word like “its” or “those,” you should know what the author is pointing to, and it doesn’t strike them as unusual when they don’t.) I am sure they struggle with long books, because it’s pretty hard and miserable to do something you can’t really do or get much out of for an extended period of time, but the underlying assumption of the piece that students are doing okay with short text is - anecdotally - wildly at odds with what I encounter. (Sorry to be like, “it’s actually so much worse,” but, well…)